
Diese Beispiel-MediaQ Application Website wurde
im Laufe des Seminars MediaQ WS14/15 erstellt.
1. Motivation
Heute möchten viele mit sogenannten Mash-Ups ihre Fotos, Videos, Events etc. in zugänglichen Plattformen überall wo es nur geht darstellen.Ein wichtiger Antrieb für die Benutzung solcher Verarbeitungsdienste sind beispielsweise motivationale Aspekte wie Community-Building, Awareness oder soziale Präsenz.
Während in der Vergangenheit eher monolytische Systeme der übliche Standard waren, sind die heutigen Systeme, die man als offen bezeichnen kann, weiter auf dem Vormarsch. Wir übersehen in diesem Zusammenhang oft, die Schwierigkeit bzw. den Anspruch, diese neu geöffneten Spielräume bzw. Potentiale der digitalen Cyberwelten besser oder auch anders zu nutzen. Was aber unserer Meinung nach somit wirklich den Markt verändern wird, ist die Kontextualität- und Personifikation neuer Anwendungen.
Jahrelang hatte man gehofft, eine neue „Killerapplikation“ – sozusagen als Nachfolge und als größeren Aufstieg unserer Zeit hervorzubringen. Google offeriert uns bislang auch nur sehr einschränkbare Suchdienste. Aber der Gedanke, dass diese Fülle von lokal verfügbarer Information mehr Bereiche beeinflussen wird als nur die Art und Weise, wie man am schnellsten die nächste Tankstelle oder Bank findet, wird in ihren Auswirkungen wohl noch immer unterschätzt. Früher und auch heute noch, nutzt man die Google Maps gerade mal überwiegend zur Reiseplanung oder zur Übersicht. Wohin führt also der Weg und was können wir noch in Zukunft von GIS-Systemen erwarten?
Wir stellen euch hier im Rahmen des MediaQ-Seminars, eine weitere Nutzung von Geoinformationen vor, nämlich realisiert am Beispiel der räumlichen Suche von Objekten in Videos.
Diese Umsetzung und Übergang exzerpiert sicherlich auch nicht gerade den „Boom Bang“ im Marketingsinne schlechthin, aber ich glaube es kann, wenn die geeigneten Schnittstellen vorhanden sind, erhebliche Einsparungen generieren, diffundierende Vernetzungen evozieren, detailnaher, zielgerichteter Komponenten durchleuchten und ein neues Nutzungserlebnis bescheren.
2. Problemdefinition
Im letzten Abschnitt wurde die behandelte Problemstellung angesprochen, welche in diesem Kapitel formaler definiert werden soll.
Es sollen alle Videos gefunden werden, die einen bestimmten Benutzer (im folgenden "B" genannt) auf ihrem Bildmaterial enthalten.
Als erstes muss dazu der relevante Feature-Raum ermittelt werden, welcher zur Lösung der Problemstellung genutzt werden kann.
Der Standpunkt, von dem aus das Video aufgezeichnet wird, kann mit zwei Dimensionen (x, y) beschrieben werden. Die zeitliche Komponente verläuft in einer dritten Dimension (t).
Insgesamt wird also ein 3D-Featureraum genutzt, in welchem einzelne Videosegment-Punkte liegen. Die Videosegment-Punkte sind Snapshots, die während der Videoaufnahme mit aufgezeichnet werden.
Zu jedem dieser Videosegment-Punkte exisitieren außerdem die Informationen über den Blickkegel der Videoaufnahme.
Durch das Verbinden der einzelnen Punkte in der zeitlichen Reihenfolge, in welcher Sie entstanden sind ergeben sich Trajektorien, die einen interpolierten Verlauf der Videoaufnahme in allen drei Dimensionen beschreiben.
Ziel ist es nun alle Videos zu finden, derer Blickkegel mindestens eine Trajektorie von "B" schneiden.
3. Algorithmische Lösung
Zur Lösung der im letzten Abschnitt gegebenen Problemdefinition muss vor allem eine Möglichkeit gefunden werden den Schnitt zwischen zeitlich veränderlichen Blickkegeln und den zeitlich bewegenden Personen (den Trajektorien) zu bewerkstelligen.
Basisalgorithmus
Dazu wurde innerhalb dieses Projekts ein Basisalgorithmus als Plane-Sweep-Algorithmus entwickelt. Als Event-Points dienen alle Videosegment-Punkte (im folgenden "S" genannt, wobei "s" ein beliebiges Element von "S" ist)
des angefragten Benutzers "B".
Jedes der Videosegment-Punkte "s" wird mit allen Videos, außer denen die zu Benutzer "B" gehören verglichen, um diejenigen zu finden, die einen Schnitt aufweisen.
Diese Schnittbestimmung wird so durchgeführt, dass für das aktuell verglichene "s" zuerst die beiden zeitlich umschließenden Teilsegmente gesucht werden. Es werden also die zwei Segmente vom betrachteten Video
gesucht, die zeitlich vor und nach dem Videosegment-Punkt "s" liegen.
Die beiden Punkte begrenzen also ein zeitliches Intervall, indem "s" liegt.
Anschließend kann ein interpolierter Punkt (im folgenden "i" genannt) zu dem Zeitpunkt von "s" ermittelt werden. Dieser Punkt hat sowohl einen interpolierten Blickkegel, als auch eine interpolierte räumlichen Position.
Durch dieses Vorgehen kann nun ein Schnittvergleich zwischen dem Kegel des interpolierten Punktes "i" und dem Punkt "s" durchgeführt werden.
Falls hier ein Schnitt vorliegt, dann gehört das Video, zu dem "s" gehört zur Ergebnismenge.
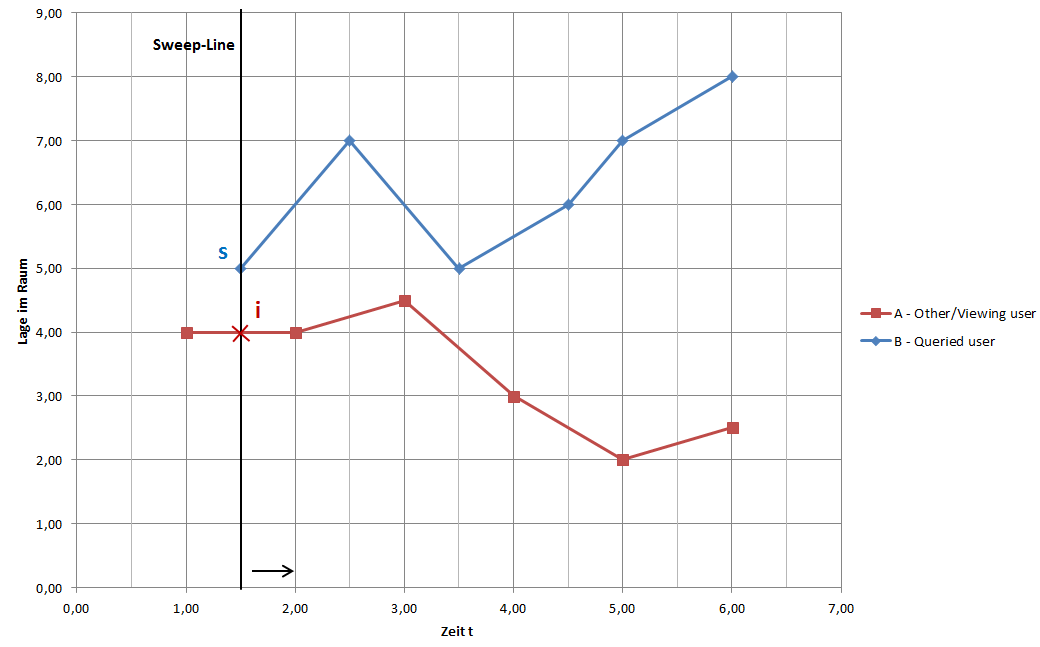
Folgende Abbildung illustriert das Vorgehen des Algorithmus. Die räumlichen Dimensionen wurden zu einer zusammengefasst,
damit das Koordinatensystem noch in 2D darstellbar ist.
Das Anfrageobjekt ist der Benutzer "B", der in diesem Beispiel ein Video aufgezeichnet hat.
Die schwarze Linie deutet die Sweep-Line an, die in der zeitlichen Dimension von links nach rechts iteriert und dabei alle
Event-Points besucht.
Als erstes wird das eingezeichnete Segment "s" untersucht. Dazu werden die zeitlichen umschließenden Segmentpunkte von "A" gesucht und ein neuer Punkt "i" wird aus diesem Intervall interpoliert.
Die Punkte "i" und "s" besitzen den gleichen Zeitstempel und somit muss nur noch geprüft werden, ob der Punkt "s" durch den Sichtkegel von "i" räumlich geschnitten wird.
Zur Bestimmung, ob ein Punkt im Schnittkegel von einem anderen Punkt liegt wird zuerst deren Abstand zueinander ermittelt. Das geschieht mit Hilfe der geographischen Koordinaten.
Die Strecke wird zuerst als Orthodrome - also als kürzeste Verbindung zwischen zwei Punkten auf einer Kugeloberfläche - im Bogenmaß berechnet (Zentriwinkel):
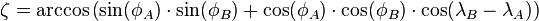
Abbildungsquelle: http://de.wikipedia.org/wiki/Orthodrome
In obiger Formel entsprechen die Lambdas den Längengrade und die Phis den Breitengrade.
Anschließend ergibt die Multiplikation dieses Zentriwinkels mit dem Erdradius (6370000 Meter) den Abstand zwischen den zwei Punkten.
Falls die beiden Punkte nun innerhalb einer bestimmten Sichtweite liegen, muss noch geprüft werden, ob der Blickkegel in die richtige Richtung zeigt. Dazu wird der Richtungswinkel (Azimuth) vom interpolierten, "sehenden" zum "gesehenen" Punkt bestimmt:
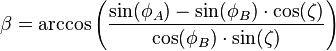
Abbildungsquelle: http://de.wikipedia.org/wiki/Orthodrome
Dadurch kann geprüft werden, ob der Azimuth innerhalb des aufgezeichneten Blickkegels liegt. Die Grenzen des Blickkegels werden berechnet, indem die aufgezeichnete Blickrichtung plus/minus dem halben Öffnungswinkel bestimmt werden.
Verbesserter Plane-Sweep Algorithmus
Der Basisalgorithmus hat natürlich viel Verbesserungspotential, da zu viele unnötige Vergleiche durchgeführt werden.
Der verbesserte Algorithmus benutzt dieselben Event-Points und ermittelt auch dieselbe Ergebnismenge, aber die Anzahl der Vergleiche wird minimiert.
Zuerst werden alle Videos vom angefragten Benutzer "B" ermittelt. Anschließend wird über jedes dieser Videos "V" iteriert. Dabei wird von der früheste und späteste Zeitpunkt von "V" ermittelt.
Außerdem werden die größten und niedrigsten x- und y-Werte ermittelt. Im 3D-Feature-Raum kann mit diesen Grenzen ein möglicher Kandidatenraum bestimmt werden.
Dazu müssen die ermittelten Grenzen aber noch um einen "Buffer" vergrößert werden, weil die Blickkegel auch eine gewisse Reichweite besitzen.
Die folgende Abbildung demonstriert das Prinzip des Kandidatenraums. Dabei wurde ein Buffer von 1,5 in allen Dimensionen gewählt.
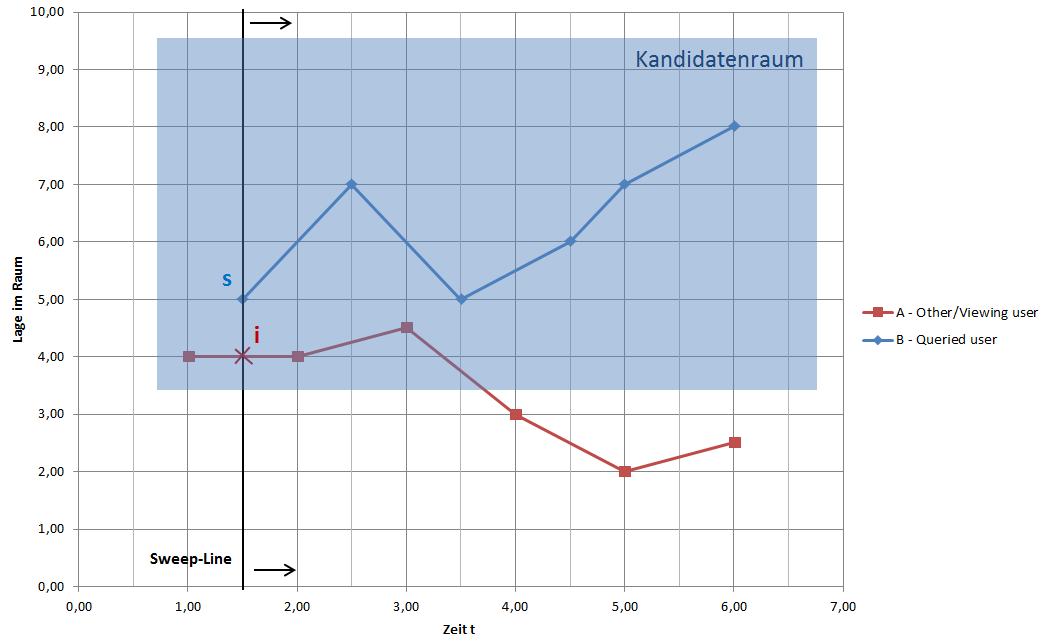
Der Kandidatenraum ist natürlich viel kleiner als der gesamte mögliche Feature-Raum, weil nur noch die Videosegmente enthalten sind, die ungefähr zur selben Zeit und am selben Ort aufgenommen wurden.
Mit großen Datenbeständen lohnt sich das einschränken natürlich immens, weil viel weniger Vergleiche durchgeführt werden müssen. Nachteil dieser Methode ist, dass für jedes Video von "B" eine neue Datenbankanfrage gemacht werden muss, während beim Basisalgorithmus nur einmal alle Datensätze angefragt werden müssen.
Aber geeignete Indizes auf den Tabellen helfen dabei diese raum-zeitlichen Anfragen auch bei sehr großen Datensätzen effizient durchzuführen.
Die zweite Verbesserung zielt auf die strenge Monotonie in der zeitlichen Dimension ab. Jeder Videosegment-Punkt "s1" ist früher als der darauf folgende "s2".
Deshalb läuft die Sweep-Line auch in der zeitlichen Dimension von links nach rechts. Nichtsdestotrotz kann diese Monotonie auch dafür genutzt werden, die zeitlich umschließden
Punkte des Kandidaten-Videos schneller zu finden. Wenn zum Beispiel die Kandidaten-Videosegment-Punkte "c1" und "c2" das Videosegment-Punktes "s1" zeitlich umschließen und der nächste zu betrachtende
Punkt "s2" zeitlich nach "c2" liegt,
dann ist bekannt, dass bei Erreichung des nächsten Event-Points "s2", der Punkt "c1" und alle davor liegenden nicht mehr umschließende untere Intervallgrenzen sein können.
Bei der Durchführung des Algorithmuses wird also für jedes Kandidatenvideo ein Index mitgeführt, der anzeigt, ab welcher Stelle überhaupt eine umschließende Intervallgrenze gefunden werden kann.
4. Technische Umsetzung
Die technische Umsetzung wurde serverseitig mit PHP relaisiert. Auf der Anwendungsseite wird HTML5 und Javascript mit JQuery/Ajax verwendet.
Wenn eine Anfrage über einen Ajax-Request durchgeführt wird, dann greift PHP auf die Datenbank des gegebenen MYSQL-Servers zu und führt alle Berechnungen,
welche im letzten Kapitel dargestllt wurden aus. Anschließend wird das Ergebnis im JSON-Format zurückgegeben.
Bei der Implementierung wurde auf die klassischen Code-Qualitätsmerkmale Wert gelegt, damit der Code möglichst wartbar und verständlich ist.
5. Einbindung der Applikation: Optimierter Sweep-Line Ansatz
6. Evaluation gegenüber Baseline
In diesem Kapitel wird eine Evualiation der Ausführungszeiten zwischen den vorher vorgestellten Baseline- und dem verbesserten Sweep-Line Ansatz durchgeführt.
Dazu wurde eine lokale Kopie der zur Verfügung gestellten MediaQ Datenbank angelegt, welche 58 verschiedene User und 279 Videos beinhaltete. Durchschnittlich hat jeder User 3,94 Videos.
Zum Vergleich der beiden Ansätze wurden drei User ausgewählt. Zuerst der User mit den meisten Videos (14 Videos) und ein User mit genau einem Videos. Anschließend wurde noch ein User mit 4 Videos ausgeählt, welcher die durchschnittliche Anzahl der Videos pro User repräsentieren soll.
Die Evaluation ist im folgenden Balkendiagramm dargestllt:
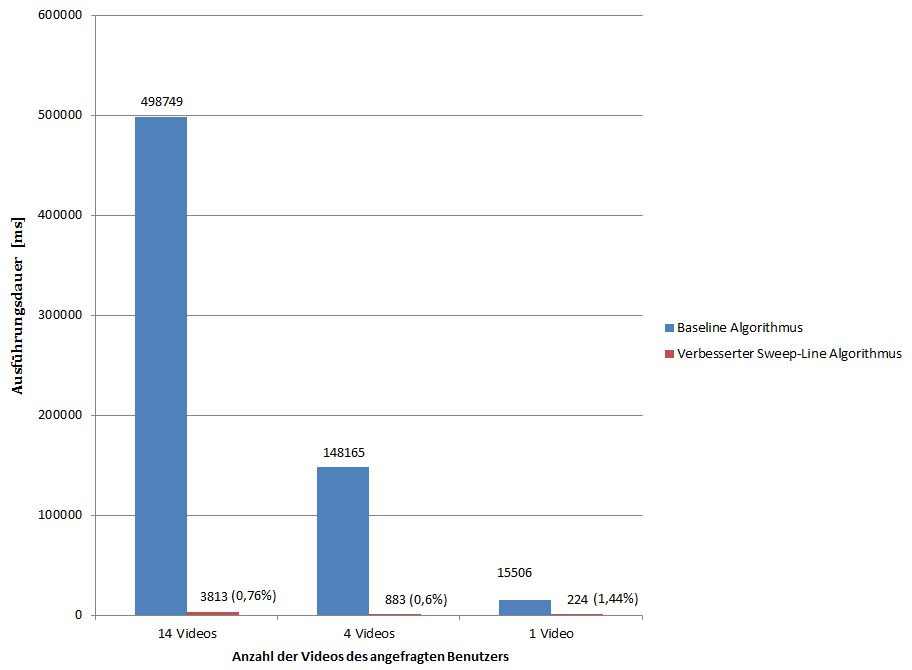
Es ist zu erkennen, dass sich die Verbesserungen deutlich auf die Ausführungsdauer des Algorhtmuses auswirken. Alle drei Zeiten des verbesserten Algorhtmuses liegen unter 4 Sekunden, wobei die Zeit mit der Anzahl der Videos, die der User selber aufgenommen hat, deutlich ansteigt.
Eine direkte Korrelation von Anzhal der Videos zur Dauer darf allerdings nicht gezogen werden, weil die Ausführungszeit von diversen anderen Faktoren abhängt, wie z.B. der gefundenen Kandidatenmenge, also denjenigen anderen Videos, die zur gleichen Zeit am gleichen Ort aufgenommen wurden.
7. Downloads
Back to top